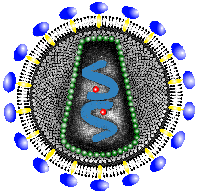
Reverse Transcriptase
HIV is a RNA virus infecting a DNA organism (human). Reverse transcriptase is used to
convert the RNA into DNA, allowing the virus to infect its host. Each red sphere
represents a reverse transcriptase. There is one reverse transcriptase associated with
each strand of RNA.
Reverse transcriptase is a very special enzyme, able to perform four distinct
functions. (1) Reverse transcriptase function converting single-stranded RNA into
single-stranded DNA, (2) DNA polymerase function converting single-stranded DNA into
double-stranded DNA, (3) RNase H function opens a place within the host DNA where the HIV
DNA will be placed, and (4) Ligase function seals the DNA at the positions where the HIV
DNA was placed. Back to Top
A HISTORICAL ACCOUNT OF DNA, RNA AND HIV.
A historical account of how we discovered that DNA is genetic material. This becomes an
important component because people have been asking about the chemical nature of HIV's
genetic material. How is information stored and transmitted in biological systems? The
answer has been discovered in this century; we should be really proud. Aristotle wrote a
treatus on how the sex of an offspring is determined. Aristotle's theory was that if
during an orgasm a man was thinking about his own pleasure the offspring would be a male.
On the other hand, if he was thinking about the partner's pleasure then the offspring
would be a female. This is not a well defined theory!
The question we want to talk about is, clearly there is information transmitted from
generation to generation and we want to ask the question where is that genetic information
stored, how is information transmitted from one generation to the next, and how is the
information stored in the genetic material actually expressed; what is the basis for
having blue eyes, what is the basis for having blond hair; what is the basis for the
expression of that genetic information?
In 1900 biology was an "infant" science, a science in its early stages. In
1900 or about that time we found out that the basis for life is based on a cellular
component. Therefore if we took an individual and broke him down to his component parts,
indeed he would be made up of cells. Virtually all organisms have a cellular basis for
their existence. That cell is the lowest structural component in living systems that
maintains all living characteristics. I can take a cell and break it down into its
molecular constituence, but when I break it down to its constituence it is no longer
alive. DNA is not alive, proteins are not alive, they are building blocks of living
systems. One of the things that happended during the 1900's was that people started
breaking down these cells and looking at their constituent components; what are the
building blocks of cells? In the building blocks of cells one would find the molecule that
contains the genetic information. It turns out that when people were chemically
characterizing cells they found that living systems were made up of mostly water. Water
obviously could not have been the genetic material because it is too simple; it could not
explain the diversity. When we break these things down we not only find there is water but
there are "simple" molecules; ions, salts, glucose, amino acids, etc. These
molecules again are too simple to explain diversity of living systems. Thus, we are
hunting for something that has the complexity to explain living systems.
When we looked at the molecular constituents of cells we found that there were some
very complicated molecules. These molecules were called macro molecules, which is an
ultimate oxymoron. When we isolated those particular molecules from cells we found that
there was a class of molecules which were going to be called polymers. Polymers are
involved in biological systems. A polymer is something that is build up of repetitive
sub-units. Each little segments of the polymer is the monomer. When we look at cellular
components we find that there are 4 large categories of macro molecular constituents that
all have a polymeric organization. Those molecules are called proteins, nucleic acids, and
nucleic acids are broken down into two types of molecules, Deoxyribonucleic acid (DNA) and
Ribonucleic acid (RNA), and then polysaccharides. These are the macro molecular
constituents and they were build up in these repetitive sub-units.
In the early 1900's chemists & biologists characterized monomeric constituents.
They chemically characterized it in protein molecules, the individual monomers were called
amino acid because they had certain chemical characteristics together. The total number of
amino acids in biological systems is 20 independent monomers that can be put together to
build a particular molecule. The nucleic acids, interestingly when we look at monomeric
constituents, are called nucleotides. The diversity of nucleotides in DNA and RNA were 4,
thus there are 4 different kinds of monomers; A's, C's, T's, and G's. The nucleotids that
make up DNA are different from the nucleotids that make up RNA. We called them generic
nucleotides, but there are differences. In sugar molecules, in polysaccharides, the
individual monomers were things called sugars. For example, if I took glucose and put it
together into a long string I would call it startch or glycogen. Even to this day we do
not know how may monomeric constituents of sugars there are because the chemistry of sugar
is more complicated than nucleotide chemistry and amino acid chemistry. We assume that
there are not that many.
In the 1900's all of these macro molecular constituents were isolated and biologists
said, the genetic information had to be stored in one of these macro molecules. They made
a big error and their error was dependent upon the following observation. They said
biological systems are tremendously diverse and we need a molecule that contains as much
as information as we can. They did the following mathematical calculation. Let me take a
protein molecule that is 150 amino acids long and they wondered how many different
proteins they can make. The answer is 20150 . For example, if I have a small
protein with 150 amino acids long and the question is how many different ones I can make,
the answer to the question is 20150, and that is a large number. Is that
molecule then diverse enough to contain all biological information? If we take nucleic
acid and there are 4 nucleotides in each position, and we make a polymer of 150
nucleotides long, how many different ones can we make? 4150. This is a big
number also but protein diversity is bigger. This is going to be their mistake, because
they were looking for potential diversity within molecules and they are going to argue
that protein molecules are the genetic material.
Today we know that when you isolate DNA from a single cell that the DNA molecule is
about 1 yard long. In 1900 biologists did not realize that nucleic acids were so long.
They thought that they were build up of units about 10 nucleotides long. The reason why
they thought it is 10 nucleotides long is that, whenever scientists are doing science they
like to make sure that their solutions are mixed. It turns out that nucleic acids, when
they are in this extended confirmation, when we take a test tube and do an experiment we
generate what are called sheer forces in the test tube and the molecule simply breaks. It
broke down to little tiny molecules about 10 nucleotides long and people looked at those
nucleic acids and said they can't be the genetic material because they can't explain the
diversity and they are so small; enough information could not have been stored in them.
The point that I want to make from this is, from about 1900 on until about 1940, the
biological community was utterly convinced that protein molecules were the genetic
material. Protein molecules did not break by sheer forces becaused they folded back in a
complex organization. Thus, the biolgoist went on thinking proteins are the genetic
material and we were wrong.
At about 1945 a very significant sequence of events happened. In 1945 we were in the
WWII. What was happening around this time is one of the biggest scientific endevours in
the history of the human race was going on called the Manhattan Project where we were
building atomic energy. We were so petrified that the Germans were going to get this that
we took every physicists that we could get our hands on. It is an amazing sequence of
events that happens in history that we actually make a bomb. I brought this up as a
background for the following reason. One of the things that happened as a result of the
Manhattan Project is a very large number of physicists got an incredibly guilty conscience
about what they did. They had unleashed the atombic bomb. Physicists looked around and
they said, how can we eleveate our guilty conscience? One of the avenues that they felt
they can do that is that they looked over the field of biology. They felt there is a
potential for applying the sophistication of technology into biomedical problems and help
mankind. The 1900's was very deterministic. Physicists looked at problems and said that if
I know where the electron are and where they were going, I should be able to determine the
course of what is going to happen in the future. All the stuff that happened in physics
from 1900 to 1945 created a relativistic world, an uncertain world in physics. Many
physicists made their reputation by establishing uncertainty principles and relativity
principles and they felt the field of physics is dead. They looked over the field of
biology and many physicists felt that if they took their sophistication of technology into
biology they can become famous if they can explain. Thus, right after WWII and around that
time there was a treamendous migration of physicists into the field of biology. The field
of biology will never recover from this invasion; biology forevermore is changed.
The first application brought into the field of biolgy in a typical physicist fashion
was an explanation of the complicated. If you have a spectrum of events that are
happening, from simple to complicated, physicists will always look at the simple system
first and make genralization in order to explain the complicated. They discovered the
simplest biological organism; a virus. Back to Top
more to come soon...
 _
_